|
|
||||
|
tutoriales |
|
Bases tecnológicas funcionales de un sistema de memoria Algoritmos de asignación y eliminación de memoria Asignación y Desasignación de la Memoria Asignar o desasignar un Bloque de la memoria Principal que tiene relacionado una Página de la memoria del Disco Duro no es tarea fácil, debido a la propiedad de Localidad (temporal, secuencial, espacial) implícita en todo programa. Debido a esta propiedad, la ejecución de un programa puede estar distribuida en varias localidades de memoria pertenecientes al mismo nivel o a niveles adyacentes. Si dichas localidades de memoria pertenecen a un mismo nivel de memoria y se cumplen las propiedades de Inclusión y Coherencia, no es necesario asignar o desasignar Bloques, Páginas o Segmentos de memoria. Si, por el contrario, las localidades de memoria están distribuidas en diferentes niveles de memoria, ocurrirá un Miss Hit, ya que será necesario asignar y probablemente desasignar localidades de memoria representadas por un Bloque, Página o Segmento de memoria, dependiendo del nivel de memoria. Antes de analizar los principios y diferentes técnicas para la asignación o desasignación de memoria, es esencial comprender el modelo para determinar la presencia de un Hit o un Miss Hit. Sólo así es posible manipular los principios de los diferentes algoritmos de asignación y desasignación de memoria. Este modelo se presenta en las figura 1.6, y en él se observan tres niveles:
Figura 1.6 Modelo de asignación y desasignación de memoria -. Nivel de Memoria Adyacente Superior: Representa la Página o Bloque a ser verificado con el fin de determinar si se cumple o no la propiedad de Inclusión entre los niveles adyacentes de memoria M y (M-1). Al nivel de memoria adyacente superior lo denotaremos con (M-1). -. Nivel de Memoria Adyacente Inferior: Representa el número de Bloques que componen el nivel de memoria inferior. Al nivel de memoria adyacente inferior lo denotaremos con la letra M. -. Nivel de Hit o Miss Hit: Dicho nivel determina si se cumple la propiedad de Inclusión entre los niveles adyacentes de memoria M y (M-1). Representaremos a un Hit con una casilla en blanco y a un Miss Hit con el signo +. En la figura 1.7 podemos observar la aplicación de dicho modelo el cual hace uso del algoritmo FIFO (First In First Out), cuyos principios serán explicados más adelante.
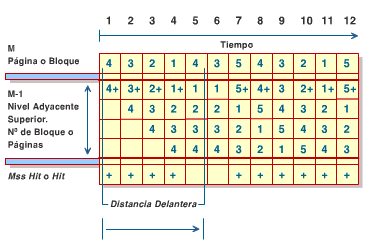
Figura 1.7 Algortimo FIFO En la figura 1.7 tambien. podemos observar una secuencia de 12 Páginas o Bloques en el nivel de memoria inferior. Esta secuencia de Páginas o Bloques recibe el nombre de Page Trace o Block Trace e indica el número de páginas diferentes que son incluidas en el nivel de memoria (M-1) durante la ejecución de un programa. En este ejemplo, el nivel de memoria superior (M-1) está compuesto por cuatro Bloques, y en el transcurso de la ejecución del programa, el mismo aloja las Páginas o Bloques pertenecientes al nivel de memoria inferior para cumplir con la propiedad de Inclusión. En el tercer nivel del diagrama de la figura 1.7 podemos observar el número total de Hits y Miss Hits en función del tiempo. En este ejemplo en particular, el porcentaje de Miss Hit es igual a 10 / 12 * 100% = 83,33%. Esto implica que el Hit Rate, durante este período de tiempo, es igual a 100% - 83,33% = 16,66%. Con base en los principios del modelo antes descrito, consideremos una secuencia de Páginas o Bloques P(i), con i desde 1 hasta n. Esto implica que el conjunto de páginas o bloques P(n) está compuesto por {s(1), s(2), s(3),..., s(n)}, donde s(i) es igual a la Página o Bloque solicitada en un tiempo ti. Definamos ahora dos distancias referenciales para las Páginas o Bloques que se repiten en un período de tiempo t. Estas dos distancias referenciales son: -. Distancia Delantera, Dt(x): La distancia delantera expresa el tiempo en el que una Página o Bloque se repite en un futuro. Esto se ilustra en el diagrama de la figura 1.8.
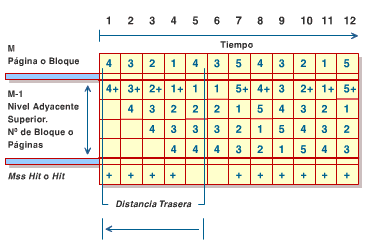
Figura 1.8 Distancia delantera -. Distancia Trasera, Tt(x): La distancia Trasera expresa el tiempo t que existe entre una Página o Bloque actual y su Página o Bloque más recientemente referenciada. Este concepto se muestra en el diagrama de la figura 1.9.
Figura 1.9 Distancia trasera Con base en los principios hasta ahora discutidos, definamos los algoritmos más resaltantes para la asignación o desasignación de un Bloque, Página o Segmento en el nivel de memoria M-1. -. Algoritmo LRU (Least Recently Used): Este algoritmo se basa en reemplazar la Página, Bloque o Segmento residente en un nivel de memoria M-1 en un tiempo dado, que posea la mayor distancia trasera. -. Algoritmo FIFO (First In First Out): Este algoritmo se basa en reemplazar la Página, Bloque o Segmento residente en un nivel de memoria M-1 en un tiempo dado, que posea el mayor tiempo como residente en ese nivel de memoria. -. Algoritmo LFU (Least Frecuently Used): Este algoritmo se basa en reemplazar la Página, Bloque o Segmento residente en un nivel de memoria M-1 en un tiempo dado, que halla sido menos referenciada en el pasado. -. Algoritmo Optimo: Este algoritmo se basa en reemplazar la Página o Bloque, residente en un nivel de memoria M-1 en un tiempo dado, que posea la mayor distancia delantera. Los principios de este algoritmo son esencialmente teóricos a menos que se haga uso de técnicas que permita cumplir con los principios de este algoritmo -Ej. La técnica de Pre-Fecth buffer, predicción de instrucciones de salto, ejecución fuera de orden, etc-, ya que en la práctica no es posible determinar la Página o Bloque que posea mayor distancia delantera, sin antes haber cumplido con la propiedad de Inclusión. |
|
© 2002 New Devices. Derechos Reservados. |