Table of Contents
Abstract
The World Wide Web technology arose in 1990 when Tim Berners-Lee pointed out the necessity of implementing an information management system to prevent the loss of information resulting from institutional structure of the European Organization for Nuclear Investigation [1].
The World Wide Web consortium was founded in October 1994 to standardize and implement protocols and to promote the evolution of a World Wide Web technology that would enable new forms of information documentation and human communication. Since then, this technology has become the most influential paradigm in the information system arena [2].
The World Wide Web technology is an information system composed of agents. Agents are programs that act on behalf of another person, entity, or process to exchange and process information [3]. Basically, in the World Wide Web technology, there are two types of agents: server agents and user agents. A server agent is a program that offers services to user agents; and a user agent is a program that uses the services offered by server agents. The World Wide Web technology is considered an application of the Internet network that has inherited many of the design principles, such as interoperability, evolution, and decentralization [4].
The interoperability design principle is assured by the implementation of compatible languages and protocols that enable access, exchange and processing of information among agents. These languages and protocols have to be implemented as simply as possible, as modular as possible, and as scalable as possible in order to facilitate:
Evolution of the World Wide Web technology.
Maintainability and decentralization of information systems.
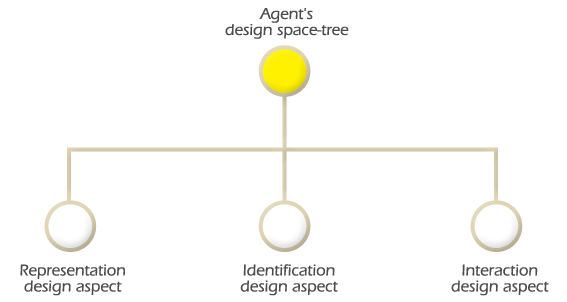
In order to comply with interoperability, evolution, and decentralization design principles, the agent's design space is composed of the following three design aspects: representation, identification, and interaction. The design space tree presented in Figure 1.1 represents the agent's design space. This design space tree model could be used to represent the general design space of the World Wide Web Technology.
The representation design aspect's function is to structure and represent the information that is stored in the agent's repository. The identification design aspect is used to identify and locate information all over the network. Once the information is represented, identified, and stored the in agent's repository, the interaction design aspect is used to access, update, replace, process or exchange information among the interconnected agents via protocols. Each of these design aspects represent a set of independent constructs that can be combined. Therefore, the representation, identification, and interaction design aspects are orthogonal.
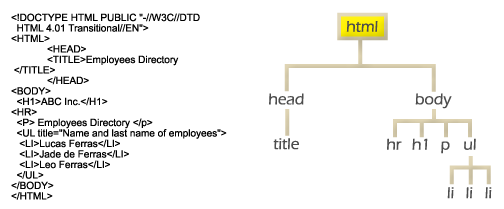
The representation design aspect uses a combination of rooted tree graphs, directed graphs, and object models to structure the information. Different types of information -text, images, and multimedia objects- can be structured in a World Wide Web document. The information contained in a World Wide Web document is structured as a rooted tree graph, where each node of the tree is treated as an object. Thus, nodes are considered as resources as well as entities that have their own identity. Each node can have attributes, content, and child nodes [5].
Figure 1.2 represents a rooted tree graph model of a hypertext markup language (HTML) World Wide Web document. This document is a resource; hence all the nodes (markups) contained in a World Wide Web document are resources. The identification design aspect locates and identifies resources; once these are identified, agents use the interaction design aspect to access, update, replace, and process or exchange resources among agents.
The representation design aspect has to be implemented in such a way that the interoperability, evolution, and decentralization design principles are preserved among agents. This explains why the World Wide Web technology designers adopted the international Standard Generalized Markup Language (SGML) to implement the specifications that represent the information of a World Wide Web document. SGML allows the implementation of a rigorous method of developing and deploying formal specifications that are used to represent information in a structured way, in order that, any hardware and software used to access information located in agents' repositories can work together [6][7].
SGML does not provide presentation format to the information. The presentation format of the information in a World Wide Web document is a function of the style sheet. Style sheets allow the information to be presented to the user in a friendly readable format. Figure 1.3 corresponds to the design space tree of the representation design aspect. The representation design space comprises two design aspects: representation and presentation.
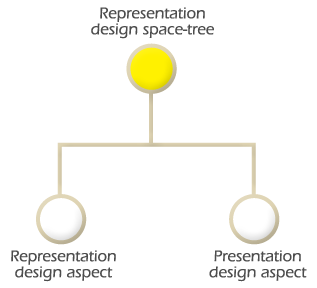
To create a World Wide Web document it is necessary to represent the information first and then present it to the user in a readable format. The function of the representation design aspect is to represent and structure the information of a World Wide Web document. The function of the presentation design aspect is to provide presentation format to the information (e.g. text format (txt), portable document format (PDF), hypertext markup language (HTML) etc).
SGML is an international standard used to define a markup language for the description and definition of marked up electronic documents. A markup is used to represent information. It indicates the meaning, structure, node name, entity, and action applied to the information. SGML is the main international standard to represent the information of electronic documents [6][7].
In order to simplify the complexities of the SGML standard, the World Wide Web designers created an SGML language subset called the Extensible Markup Language (XML) specifications [8]. An XML document is a valid SGML document because XML is a subset of SGML. WWW technology specifies XML as the main mark up language for the description and definition of marked up electronic documents and marked up languages. The formal method of describing the XML syntax is the Extended Backus-Naur Form (EBNF) notation, a syntax used to define the elements and attributes that make up a custom language.
Figure 1.4 represents the general structure of a markup. A markup is composed of the following components: Start-tag, Content, and End-tag.

The start tag comprises: the start-tag open and close delimiters, node name, attributes name, value indicator, attributes value delimiters, and the attributes value. The function of the start-tag, along with the end-tag, is to represent information (content component) indicating: the node name (identity), entity, and action applied to the information. A document type definition (DTD), which is a design aspect of an SGML document, is used to define the structure hierarchy for each of the markup elements (nodes) that form an XML document. The relation of each of these markups can be modeled with a rooted tree graph, where each node (markup) of the tree is treated as an object. Therefore, each markup element is considered as an entity that has identity.
Three design aspects compose the design space tree of an SGML document: Document Declaration, Document Type Definition, and Document Instance. Figure 1.5 represents the design space tree of an SGML document.
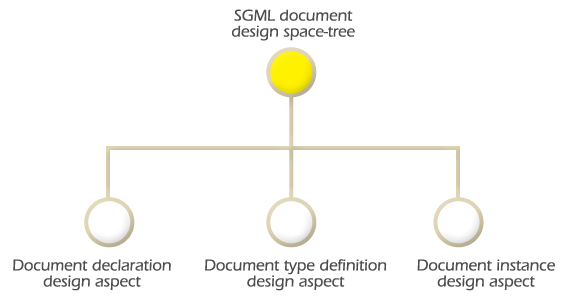
The role of the document declaration is to ensure interoperability among agents. This is achieved by defining rules that govern the interpretation of marked up information among agents. The main set of rules involves the definition of allowed character sets, characters used as control characters (e.g. start-tag open and close delimiters), and object capacities. In order to assure interoperability among agents every document type definition is associated to a document declaration.
The document type definition (DTD) defines the rules that govern the physical structure of a document instance. The DTD is used to define the markups that will represent the information in the document instance. A DTD is also used to define the logical structure of document models. In this way, the normalization of document instances is feasible allowing communities to share information more easily.
The function of a document instance is to markup the author's information based on the rules defined in the document declaration and document type definition. Once a DTD has been designed, multiple document instances can be defined.
Contrary to SGML, the document declaration of the XML specifications is fixed [1] , and authors are not allowed to change any part of the XML document declaration. This decision was taken by the members of the W3C consortium in order to simplify the design process of XML documents.
Software agents read the document declaration in order to establish rules for interpreting document type definition and document instances. Once the rules are established, software agents verify that document type definition and document instance follow the rules. Software agents also verify that document instances respect the logical structure defined in the DTD.[2]
The identification design space locates agents, identifies resources stored in agents' resource repositories, and indicates to the interaction design space the access mechanism of resources. In order to comply with interoperability, evolution, and decentralization design principles, World Wide Web technology designers created the Uniform Resource Identifier (URI) Internet standard [10]. A URI is used to locate, identify, and indicate the access method of resources stored in agents' repositories. As a result, URI is the main identification method of resources of World Wide Web technology [3]. Figure 1.6 represents the design aspects of the design space tree of the identification design aspect.
The Uniformity design aspect consists of the common interpretation of different types of resource identifiers among agents. The resource design aspect is the conceptual mapping to a resource or set of resources. The identifier design aspect is an object that can act as a reference to something that has an identity [10]. Each of these design aspects will be explained in detail in chapter 3.
Once information is represented and identified, the interaction design aspect is used to program the interaction between server agents and user agents. Such interaction defines a Web service. As a result, Figure 4.1 represents the design space tree of Web services. Such design space tree is composed of the following design aspects: message, resource, service, and policy.
The interaction between provider entities and requester entities is based on the exchange of messages. Therefore, the role of the message design aspect is to define the structure of a message and on the other hand, the purpose of the resource design aspect is to reference resources with URIs. As a result, requester entities are able to locate and identify the services offered by provider entities[3]. Once messages are defined and identified, the service design aspect defines the way messages are exchanged and processed between provider entities and requester entities and the role of the policy design aspect is to define the behavior of provider entities and requester entities applying policies to the service, message, and resource components.
[1] Note by James Clark regarding the comparison of SGML and XML. http://www.w3.org/TR/NOTE-sgml-xml.
[2] Basically, this is one of the functions of the parser, a program for deconstructing a character string or a set of character strings into its constituent parts and identifying those parts according to a set of rules.
[3] The community that programs a server agent in order to offer services to users is known as a Provider Entity and users that use a user agent to consume the services offered by a provider entity are known as a Requester Entity.