Table of Contents
Abstract
The role of the representation design space is to represent, structure, and normalize information of any community activity and then present the information to the user in a readable format. In order to comply with interoperability, evolution, and decentralization design principles, the World Wide Web technology designers created an SGML language subset called the Extensible Markup Language (XML). As a result, the World Wide Web technology specifies XML as the main markup language for the definition of World Wide Web markup electronic documents and markup languages.
The following two design aspects compose the representation design space: representation and presentation. These two design aspects allow the separation of the document.s information from its presentation format. The role of the representation design aspect is to structure and normalize information of any community activity. The role of the presentation design aspect is to provide appearance and format for the information.
XML specifications are the main specifications in World Wide Web technology to represent information. Figure 2.1 represents the design space tree for the creation of XML document instances and the definition of XML languages. It is composed of two design aspects: document model and document instance.
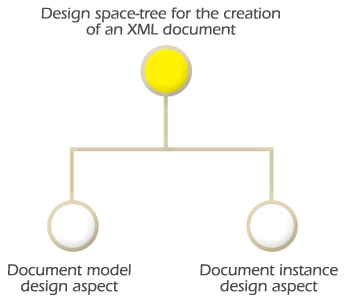
The document model design aspect is used to define the structure hierarchy for each of the markup elements (nodes) that compose an XML document instance. The structure hierarchy represents the logical structure of information. The document model also defines the structure rules that govern an XML document instance. The role of a document instance is to markup information based on the rules defined in the document model. In this manner, the normalization of XML document instances is feasible, allowing communities to share information more easily. Once a document model has been designed multiple document instances can be created [4]
In the actual World Wide Web, either of the following specifications are used to model XML documents: Document Type Definition (DTD) and XML Schema.
DTD specifications are part of the XML specifications. A DTD is used to define the structure hierarchy for each of the markups elements (nodes) that compose an XML document instance. The relation of each of these markups can be modeled with a root tree graph, where each node (markup) of the tree is treated as an object. Therefore, each markup element is considered as an entity that has identity and it can be identified by a Universal Resource Identifier (URI) [5].
A DTD is composed of the following components:
Element
Attribute
Entity
Notation
The element component defines the hierarchy and markup declaration, giving its name and content model. The content model defines if the element is empty, has only data, or has a sequence of child nodes. The generic syntax to define an element component is:
<!ELEMENT element-name (element-content)>
Elements can contain the following type of data: ANY, #CDATA, #PCDATA. ANY means that an element can contain any type of data. #CDATA is character type data. And #PCDATA is character data that must be parsed and expanded.
In order to specify how many instances an element can have in an XML document the following characters are used by each element name:
Table 2.1. Element instances
| Element | Instances |
|---|---|
| None | must occur only 1 time |
| * | Occur 0 or more times |
| + | Occur 1 or more times |
| ? | Occur exactly 0 or 1 time |
The attribute component defines additional information about an element contained within a start-tag, in the form of a name and value separated by a value indicator. The generic syntax to define the attributes of an element is:
<!ATTLIST element-name attribute-name attribute-type default-value>
An attribute can be defined with any of the following attribute types and values:
Table 2.2. Attribute types
| Type | Description |
|---|---|
| CDATA | Character data |
| ENTITY | An entity |
| ENTITIES | List of entities data |
| ID | Unique ID Data |
| IDREF | ID of another element |
| IDREFS | List of IDs of other elements |
| NMTOKEN | XML name data |
| NMTOKENS | List of XML names |
| NOTATION | Name of a notation |
| (val1 | val2 | .) | List of values |
| XML | Predefined value |
Table 2.3. List of values
| Type | Description |
|---|---|
| #DEFAULT value | If no value exists in the XML document instance, the value specified in the DTD will be used |
| #FIXED value | If the value defined in the XML document instance is different from the value specified in the DTD document model, the XML processor will signal an error |
| #IMPLIED | The value does not have to be supplied in the XML document instance |
| #REQUIRED | If the XML document instance does not have a value, an error will occur |
The entity component in a DTD is a component whose value requires interpretation and action in order to reuse the information that it contains. The general syntax of an entity component is:
<!ENTITY entity-name "entity-value">
The notation component allows us to include non-XML data in documents by describing the format of this non-XML data and allowing the application to recognize and handle this data. The generic syntax of the notation element is:
<!NOTATION name system "external_ID">
Based on these premises let us model a very basic employee directory XML document. This document will represent the first name and last name of all employees of a company. As a result, the following file .directory.dtd. represents the DTD document of the employee directory:
Line 1 <?xml version="1.0" encoding="UTF-8"?> Line 2 <!ELEMENT company (employees_directory, author)> Line 3 <!ELEMENT employees_directory (employee+)> Line 4 <!ELEMENT employee (first_name, last_name)> Line 5 <!ELEMENT last_name (#PCDATA)> Line 6 <!ELEMENT first_name (#PCDATA)> Line 7 <!ELEMENT author (#PCDATA)> Line 8 <!ATTLIST company name CDATA ""> Line 9 <!ENTITY copyright "All rights reserved">
This DTD file is used to define the logical structure of the employee directory document. The first line represents the DTD document prolog, which must precede any element. This prolog contains a markup that represents a processing instruction to the XML processor. The tag open and close delimiters of a DTD document prolog are <? and ?>. This processing instruction indicates to the XML processor: the XML version .1.0. and the character encoding used that in this case is UTF-8. The XML specifications require that XML processors implemented in agents support the character encoding UTF-8 and UTF 16. The UTF-8 is the default. Agents can also support additional character encoding such as: ISO-8859, ISO-2022-P, shift_JIS, EUC-P for JIS X-0208-1997, and character encodings that are registered with the Internet Assigned Numbers Authority (IANA). The international standard to represent all characters used in all written languages including all mathematical and other symbols is the Universal Multiple Octet Coded Character Set (ISO/IEC 10646). It provides the basis for internationalization of information systems. UTF-8 and UTF-16 are part of ISO/IEC 10646 specifications. [22][23][24]
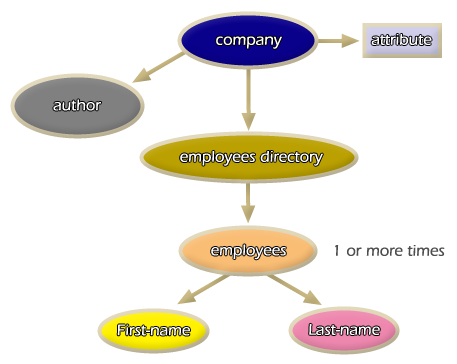
Lines two, three, and four define the logical tree graph structure of the DTD document model. This logical tree is as follows:
The element: <!ELEMENT company (employees_directory, author)> defines the element company as the root node of the tree graph, whose children are the nodes: employees_directory and author.
The element <!ELEMENT employees_directory (employee+)> defines the employees_directory node whose children nodes employee+ can have one or more instances.
The element <!ELEMENT employee (first_name, last_name)> defines the employees node whose children nodes: first_name and last_name can have only one instance.
Lines five, six, and seven indicate the type of information that last_name, firts_name, and author nodes can contain. Line 8 defines an attribute for the root node company. And line 9 defines an entity in order to reuse the following information: .All rights reserved. in any document instance. This DTD document model can be represented by the root tree graph presented in Figure 2.2.
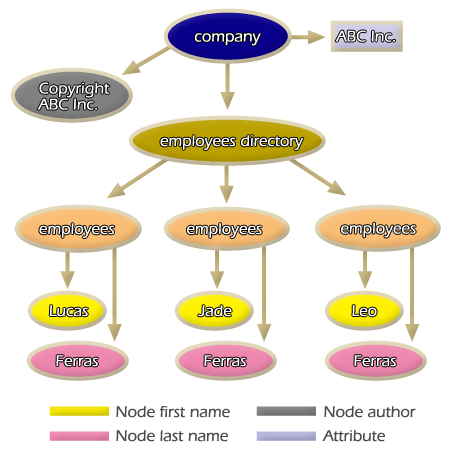
Now that the structure hierarchy for each of the markups elements that compose the employee directory document model has been defined, an XML document instance can be created. The following XML file .directory.xml. is an instance of the DTD document model directory.dtd:
Line 1 <?xml version="1.0" encoding="UTF-8"?> Line 2 <!DOCTYPE company SYSTEM "directory.dtd"> Line 3 <company name="ABC Inc."> Line 4 <employees_directory> Line 5 <employee> Line 6 <first_name>Lucas</first_name> Line 7 <last_name>Ferras</last_name> Line 8 </employee> Line 9 <employee> Line 10 <first_name>Jade</first_name> Line 11 <last_name>De Ferras</last_name> Line 12 </employee> Line 13 <employee> Line 14 <first_name>Leo</first_name> Line 15 <last_name>Ferras</last_name> Line 16 </employee> Line 17 </employees_directory> Line 18 <author>IBC Inc. ©right;</author> Line 19 </company>
The first line defines the processing instructions of the XML document. This line indicates to the XML processor the XML version number, the character set used, and if the declaration of the document is standalone or not. In this case, this XML document is an instance of the document model .directory.dtd.. This XML document instance is not a standalone XML document. Therefore, the attribute standalone is not written explicitly (standalone=.no.).
The second line indicates the document model associated to the XML document instance .directory.dtd.. Markups: company (root node), employees_directory, employee, first_name, last_name, author, and entity .copyright. are just instances of the elements defined in the document model .directory.dtd.. The root tree graph structure for this XML document (directory.xml) is presented in Figure 2.3.
The XML Schema specifications are used to define document models like the XML DTD. The XML Schema specification is an XML language application. The main difference between XML DTD and XML Schema is that authors using the XML Schema specifications have the capability to define robust rules that can be used by any programming language to validate the content and data types of XML markup instances.
The implementation of content and data type rules in XML Schema document models provides many benefits to communities. Some of these advantages are: Reuse of XML Schema in other XML Schema; reference multiple XML schemas from the same XML document instance; support of Uniform Resource Names (URN) in order to avoid collisions among XML document instances; and the normalization of rules that define the content of XML markup instances.
On the other hand, content model and data type validity allows the implementation of robust rules that can be used by any programming language enabling the unification of both document modeling and data modeling (relational database). Therefore, the information exchanging process among communities is more robust and simple.
The XML schema specifications basically define thirteen kinds of components:
Simple type definitions
Complex type definitions
Attribute declarations
Element declarations
Attribute group definitions
Identity-constraint definitions
Model group definitions
Notation declarations
Annotations
Model groups
Particles
Wildcards
Attribute Uses
The Simple type, Complex type, Attribute declarations, and Element declarations components are known as the primary components. The simple and complex type components are used to define the root tree hierarchy of the XML document model, and the attribute and element declaration components associated with a complex or simple type component are used to define the markup element model. Complex type components may include simple type, element, and attribute declaration components. However, simple type components cannot include element content and attribute declaration components. The Attribute group definitions, Identity-constraint definitions, Model group definitions, and Notation declarations components are known as secondary components. Finally, the components Annotations, Model groups, Particles, Wildcards, and Attribute uses are know as the helper components [6].
The following XML schema document: directory.xsd represents the document model for the XML document instance directory-schema.xml.
-------------------------------------------Section 1-------------------------------------- <?xml version="1.0" encoding="UTF-8"?> <xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" elementFormDefault="qualified"> -------------------------------------------Section 2-------------------------------------- <xs:element name="company"> <xs:complexType> <xs:sequence> <xs:element name="employees_directory" type="employees_directoryType"/> <xs:element ref="autor"/> </xs:sequence> <xs:attribute name="name" type="xs:string" default="ABC Inc."/> </xs:complexType> </xs:element> --------------------------------------------Section 3------------------------------------- <xs:complexType name="employees_directoryType"> <xs:sequence> <xs:element name="employee" type="employeeType" maxOccurs="unbounded"/> </xs:sequence> </xs:complexType> ---------------------------------------------Section 4------------------------------------ <xs:complexType name="employeeType"> <xs:sequence> <xs:element ref="first_name"/> <xs:element ref="last_name"/> </xs:sequence> </xs:complexType> ----------------------------------------------Section 5----------------------------------- <xs:element name="autor" type="xs:string"/> <xs:element name="first_name" type="xs:string"/> <xs:element name="last_name" type="xs:string"/> ------------------------------------------------------------------------------------------ </xs:schema>
The first section of the document defines the processing instructions of the XML document and the URN namespace .xs:.. The second section defines the root element of the tree graph, where the markup <xs:element name="company"> includes the definition of a complex component that defines the sequence of children nodes: employees_directory and author. And it includes the attribute ABC Inc. The employees_directory element is defined by the complex component employees_directoryType.
The next one defines the complex component: employees_directoryType. This component includes the element .employee., which is defined by the complex component named employeeType. This element can be repeated as many times as needed in the XML document instance.
The fourth section defines the complex component employeeType. This component is used to define the elements that it includes, which are: first_name and last_name. Each of these elements is defined by a simple type component included in the fourth section. In the fifth section three simple type components are defined in order to define the elements: author, first name and last name with their respective data type. The data type of each of these elements is string. The root tree graph for this document model is the same as the one presented in Figure 2.2.
The following XML document "directory-schema.xml" is a document instance of the XML Schema "directory.xsd" whose graph structure is the same presented in Figure 2.3.
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE company SYSTEM "directory.xsd"> <company name="ABC Inc."> <employees_directory> <employee> <first_name>Lucas</first_name> <last_name>Ferras</last_name> </employee> <employee> <first_name>Jade</first_name> <last_name>De Ferras</last_name> </employee> <employee> <first_name>Leo</first_name> <last_name>Ferras</last_name> </employee> </employees_directory> <autor>ABC Inc. ©right;</autor> </company>
As you can see, XML DTD and XML Schema specifications allow authors to customize the structure of XML documents instances by defining XML document models. XML DTD or XML Schema defines the rules that govern the physical structure of document instances. Thus, the normalization of document instances allows communities to share and process information more easily.
Once a document model is created with XML Schema or DTD, XML document instances are edited and validated by XML processors. When XML document instances respect the rules defined by its associated document model, XML document instances are known as valid well-formed XML document instances. XML processors implemented in software agents are able to determine well-form XML document instances when it deconstructs the set of character strings that compose the XML document into its constituent parts and identifies those parts according to the set of rules defined in the set of XML specifications. To be valid, an XML document does not necessarily have to have an associated document model. This is because an XML document can be a standalone XML document and if it respects the XML syntax, this XML document is considered a well-formed XML document . The main disadvantage of using standalone XML documents is that the content of each XML markup is not normalized against a document model. As a result, the XML processor cannot do the validation process of information, it has to be programmed.
As was explained previously, the relationship of each XML markup instance can be modeled with a root tree graph, where each markup (node) of the tree is a resource that has an identity. Therefore, each XML markup is identifiable with a Universal Resource Identifier (URI) [7]. A markup instance is used to represent information. It indicates the meaning, structure, node name (identity), entity, and action applied to the information. Due to the fact that a URI can identify any XML resource, the World Wide Web technology designers created a set of XML languages specifications to establish relations between XML resources using URIs. In this manner, the meaning of information is given by explicit relation of resources. These relations provide semantic to information (Semantic Web) that make it possible for automated software agents and communities to process information in cooperation. Semantic Web is based on the Resource Description Framework specifications (RDF), which integrates a variety of applications using XML for syntax and URIs for naming. [25]
RDF is an XML application language designed to represent relations between World Wide Web resources (e.g., XML resources, images, HTML documents, etc.) through the definition of simple statements, whose resources are identified by URIs.
The representation structure of World Wide Web resources using RDF specifications is composed of a collection of the following set of elements: subject, predicate and object. This set of elements is known as a triple, which is the fundamental structure to establish RDF relations between World Wide Web resources. It can be modeled with the directed-arc graph presented in Figure 2.4, whose elements .subject. and .object. are the nodes of the graph and the predicate element is the arc. The resource of the object element can be defined by constant values (e.g., the international standard two-letter code for Italian language "IT"), therefore the object node is represented by a square rather than ellipses. Only object elements can have constant values.

The subject element identifies a statement made to a World Wide Web resource. The predicate element identifies the property of the statement, whose statement was defined by its related subject element. Then there is the object element that identifies the value of property statement, whose property is defined by its related predicate element.
The assertion of an XML RDF directed-arc graph says that some relationships between the subject element and object element are indicated by the predicate element of the triple. The assertion of an XML RDF document is the total number of triple statements that it contains, therefore the meaning of an XML RDF document is the conjunction (logical AND) of the statements represented by the triples it contains [8].
Due to the fact that triple elements are identifiable by URIs to avoid collisions among RDF statements, each element can be associated to a namespace (Uniform Resource Name). When a set of elements are mapped to a URI namespace each namespace can be used to represent vocabularies that communities can use in order to normalize the relations of resources. As a result, World Wide Web technology designers created RDF Schema specifications to allow communities to define vocabularies they need to use in their XML-RDF statements [9].
Based on these premises, let us create the following XML-RDF document "ABC.rdf": The company ABC Inc. has a set of XML resources that were created by the following departments: Human Resources and Development. Therefore, ABC Inc. would like to create an XML-RDF document "ABC.rdf" where every XML document instance is related to the department to which it belongs. The relations have to be implemented with the Dublin Core vocabulary and have to include the Dublin Core predicates "language, date, and creator".
The set of XML documents that have to be included in the XML-RDF document .ABC.rdf. are:
employees-directory.xml -> Human Resources.
phone-directory.xml -> Human Resources.
xml-processor-ver1.xml -> development.
xml-processor-ver2.xml -> development.
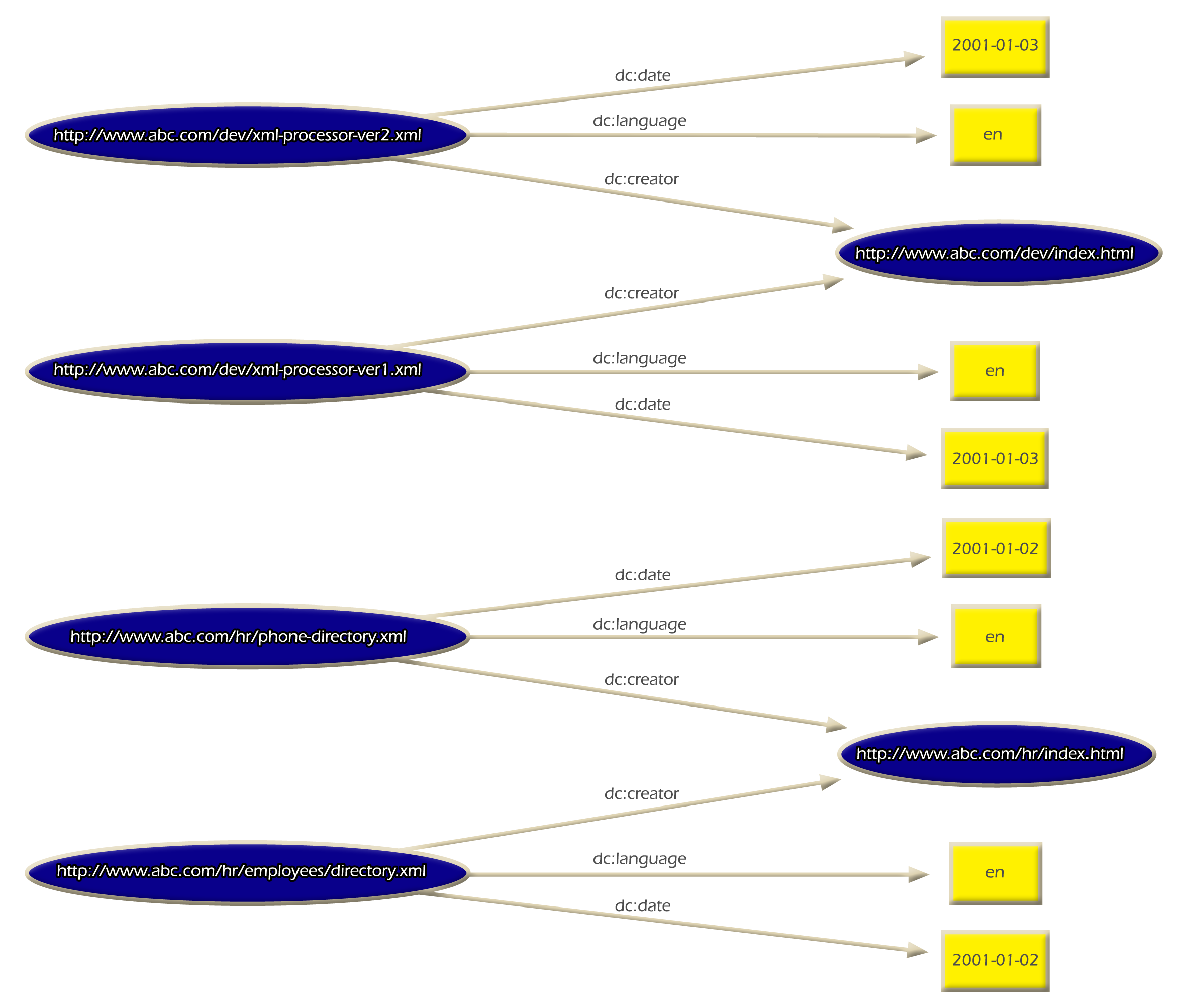
The following triples (Subject, Predicate, and Object) represent the above statements. Where triples 1, 2, and 3 defines the statement associated to resource employees_directory.xml. As you can see, each of the subjects, predicates, and objects associated to this statement are reference by URIs, except the constant values defined for the objects of statement 1 and 2:
1. <http://www.abc.com/hr/employees-directory.xml> <http://purl.org/dc/elements/1.1/date> "2000-01-02" . 2. <http://www.abc.com/hr/employees-directory.xml> <http://purl.org/dc/elements/1.1/language> "en" . 3. <http://www.abc.com/hr/employees-directory.xml> <http://purl.org/dc/elements/1.1/creator> <http://www.abc.com/hr/index.html> . 4. <http://www.abc.com/hr/phone-directory.xml> <http://purl.org/dc/elements/1.1/date> "2000-01-02" . 5. <http://www.abc.com/hr/phone-directory.xml> <http://purl.org/dc/elements/1.1/language> "en" . 6. <http://www.abc.com/hr/phone-directory.xml> <http://purl.org/dc/elements/1.1/creator> <http://www.abc.com/hr/index.html> . 7. <http://www.abc.com/dev/xml-processor-ver1.xml> <http://purl.org/dc/elements/1.1/date> "2000-01-02" . 8. <http://www.abc.com/dev/xml-processor-ver1.xml> <http://purl.org/dc/elements/1.1/language> "en" . 9.<http://www.abc.com/dev/xml-processor-ver1.xml> http://purl.org/dc/elements/1.1/creator <http://www.abc.com/dev/index.html> . 10. <http://www.abc.com/dev/xml-processor-ver2.xml> <http://purl.org/dc/elements/1.1/date> "2000-01-02" . 11. <http://www.abc.com/dev/xml-processor-ver2.xml> <http://purl.org/dc/elements/1.1/language> "en" . 12.<http://www.abc.com/dev/xml-processor-ver2.xml> <http://purl.org/dc/elements/1.1/creator> <http://www.abc.com/dev/index.html>
The first three statements say:
Resource .directory-employees.xml. was created on 2000-01-02.
Resource .directory-employees.xml. language is English.
Resource .directory-employees.xml. was created by Human Resources Department.
The rest of the statements are self-explanatory. Figure 2.5 represents the directed-arc graph for the set of triples explained above.
In order for the XML-RDF processors to be able to process each of these statements, each statement has to be included in the following XML-RDF document "ABC.rdf":
Line 1. <?xml version="1.0" encoding="UTF-8"?> Line 2. <rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> Line 3. <rdf:Description rdf:about="http://www.abc.com/hr/employees-directory.xml"> Line 4. <dc:date>2000-01-02</dc:date> Line 5. <dc:language>en</dc:language> Line 6. <dc:creator rdf:resource="http://www.abc.com/hr/index.html"/> Line 7. </rdf:Description> Line 8. <rdf:Description rdf:about="http://www.abc.com/hr/phone-directory.xml"> Line 9. <dc:date>2000-01-02</dc:date> Line 10. <dc:language>en</dc:language> Line 11. <dc:creator rdf:resource="http://www.abc.com/hr/index.html"/> Line 12. </rdf:Description> Line 13. <rdf:Description rdf:about="http://www.abc.com/dev/xml-processor-ver1.xml"> Line 14. <dc:date>2000-01-03</dc:date> Line 15. <dc:language>en</dc:language> Line 16. <dc:creator rdf:resource="http://www.abc.com/dev/index.html"/> Line 17. </rdf:Description> Line 18. <rdf:Description rdf:about="http://www.abc.com/dev/xml-processor-ver2.xml"> Line 19. <dc:date>2001-01-03</dc:date> Line 20. <dc:language>en</dc:language> Line 21. <dc:creator rdf:resource="http://www.abc.com/dev/index.html"/> Line 22. </rdf:Description> Line 23. </rdf:RDF>
The first line of this XML-RDF document defines the processing instruction of the XML document and the encoding method "UTF-8". The root node of the XML document and the following URI references "http://www.w3.org/1999/02/22-rdf-syntax-ns#" and "http://purl.org/dc/elements/1.1/" are defined in line 2. They are also used to define the XML namespaces "rdf:" and "dc:". The namespace "rdf:" is used for RDF vocabulary and namespace "dc:" is used for Dublin Core vocabulary. Line 3 corresponds to the subject element "employees_directory.xml". Lines 4, 5, and 6 define the associated predicates and objects of employees-directory.xml resource. Finally, line 7 represents the end tag of markup <rdf:description>. The rest of the XML-RDF statements are self-explanatory.
Once XML-RDF documents are created and validated XML-RDF processors are able to process them. Actually, there are quite a few XML-RDF applications two of the most known RDF applications are the Dublin Core Metadata Initiative (DC) and the RDF Site Summary (RSS). Dublin Core is composed by a set of "elements" used to describe documents. Its goal is to provide the necessary vocabulary to facilitate the description and the automated indexing of documents. The current Dublin Core vocabulary contains the definition for the following terms [26]:
Title: A name given to the resource.
Creator: An entity primarily responsible for making the content of the resource.
Subject: The topic of the content of the resource.
Description: An account of the content of the resource.
Publisher: An entity responsible for making the resource available
Contributor: An entity responsible for making contributions to the content of the resource.
Date: A date associated with an event in the life cycle of the resource.
Type: The nature or genre of the content of the resource.
Format: The physical or digital manifestation of the resource.
Identifier: An unambiguous reference to the resource within a given context.
Source: A reference to a resource from which the present resource is derived.
Language: A language of the intellectual content of the resource.
Relation: A reference to a related resource.
Coverage: The extent or scope of the content of the resource.
Rights: Information about rights held in and over the resource.
The RDF Site Summary (RSS) is composed of the following vocabularies:
The title: element is a name given to a resource.
The description element is a brief description about the content of the resource.
The item element is always associated to the URL that points to the resource.
In this manner, communities are able to program agents in order to access a variety of information on the Web on a day-to-day basis such as news headlines, schedules, etc[10].
In conclusion, XML is the main markup language for the definition of World Wide Web markup electronic documents and markup languages. XML provides the syntax for structured documents, but imposes no semantic constraints on the meaning of these documents. RDF specifications are a set of XML application languages used to provide semantics among World Wide Web resources based on statements.
Once document models are created with XML Schema or DTD, XML document instances are edited and validated. Then, XML document instances are considered ready to be processed or used by an XML enabled framework. This step may involve the transformation of XML resources to a specific presentation format.
Extensible Style Sheet Language specifications (XSL) are the main specifications in the World Wide Web technology to transform the content of XML resources to a specific presentation format. XSL is an XML application language used by authors to create style sheets that transform the content of XML resources to a presentation format (e.g., HTML, TXT, PDF). The design space tree of XSL style sheets is composed of the following design aspects: transformation and format. [27]
The role of the transformation design aspect is to select from a given set of XML resources all the XML resources whose content will be presented to users. This selection process is known as tree transformation. Figure 2.6 represents a generic view of the transformation process, where a set of XML source resources .XML root graph source tree. is transformed to an XML result tree .XML root graph result tree., whose content is formatted to a specific presentation format. The XML result tree includes all the formatting semantics, therefore every node of the XML result tree are formatting objects.
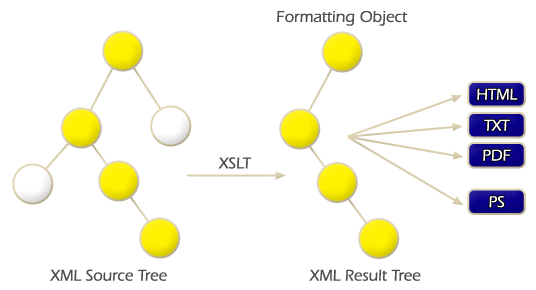
The Extensible Language Style Sheet Transformation specifications (XSLT) and Extensible Markup Language Path (XPath) specifications are part of the XSL specifications. These specifications are used to transform XML source resources. The XLST specifications is an XML language application for transforming XML source resources to an XML result tree, and XPath specifications is an expression language used by XSLT to access or refer XML nodes [11]. In order to accomplish the transformation process, the XSLT specifications define a set of XSLT elements and XSLT functions to select and transform XML source resources to an XML result tree [12].[21][28]
The function of the format design aspect is to allow authors to implement formatting procedures. Such procedures are executed by a formatter. A formatter is implemented in server agents or user agents. The Extensible Style Sheet Formatting Object specifications (XSL-FO) are the main specifications in the World Wide Web technology to define format procedures which are applied to the content of XML result trees [13].[27]
The following XML document "directory.xml" represents the XML employee.s directory document instance viewed in the previous section:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE company SYSTEM "directory.dtd"> <?xml-stylesheet type="text/xsl" href="directory.xslt"?> <company name="ABC Inc."> <employees_directory> <employee> <first_name>Lucas</first_name> <last_name>Ferras</last_name> </employee> <employee> <first_name>Jade</first_name> <last_name>De Ferras</last_name> </employee> <employee> <first_name>Leo</first_name> <last_name>Ferras</last_name> </employee> </employees_directory> <autor>IBC Inc.</autor> </company>
As you can see the third line of this XML document instance indicates to the XML processor that this file is associated with the following XSLT document instance "directory.xslt":
<?xml version="1.0" encoding="UTF-8"?> <xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="/"> <html> <head> <title>ABC Inc. Employees directory</title> </head> <body> <xsl:for-each select="company"> <xsl:for-each select="@name"> <p style="color:#000080; font-family:Times New Roman; font-size:xx-large"> <xsl:value-of select="."/></p> </xsl:for-each> <xsl:for-each select="employees_directory"> <p style="color:#000000; font-family:Times New Roman; font-size:large">Employees Directory</p> <xsl:for-each select="employee"> <p>-. <xsl:for-each select="first_name"><xsl:apply-templates/> </xsl:for-each>, <xsl:for-each select="last_name"><xsl:apply-templates/> </xsl:for-each></p> </xsl:for-each> </xsl:for-each> </xsl:for-each> </body> </html> </xsl:template> </xsl:stylesheet>
Line 1 and 2 are self-explanatory. Line 3 defines a HTML presentation format template [14]. This template is applied to the root node of the result tree, where the following XML node instances: <company>, <employees_directory>, <employee>, <first_name>, and <last_name> are selected using the following set of XSLT elements: <xsl:for-each select=.xml node name.> and <xsl:apply-template/>. The XSLT element <xsl-for-each select=.xml node name.> is used to loop through each node to select the child nodes contained in the specified node set. And the XSLT element <xsl:apply-template/> is used to apply the defined presentation format template to each of the selected XML nodes instances.
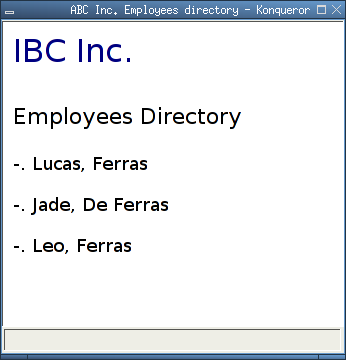
Once XML processors that support the set of XSL specifications parse the presented XML document instance .directory.xml., the content of the XML result tree is presented to the user with the Hypertext Markup Language (HTML) presentation format. Figure 2.7 represents such HTML document [15].
[4] An XML document instance that does not have an associated document model . DTD or XML schema . is known as standalone XML document.
[5] Chapter 3 explains in detail the Identification Design Aspect, where a URI is the main identification method of resources of World Wide Web technology.
[6] Details for each of these components can be found in the following URLs http://www.w3.org/TR/xmlschema-0/, http://www.w3.org/TR/xmlschema-1/ and http://www.w3.org/TR/xmlschema-2/
[7] A URI is the main identification method of resources of the World Wide Web technology. Also, a URI is the main component of the identification design aspect. See chapter 3 for details on this topic.
[8] A formal explanation of the meaning of XML RDF graphs can be found at http://www.w3.org/TR/rdf-mt/
[9] The latest RDF Schema specifications can be found at http://www.w3.org/TR/rdf-schema/
[10] The following resource http://www.w3.org/2000/08/w3c-synd/home.rss is an example of an XML-RSS document.
[11] XPath specifications are part of the identification design aspect.
[12] The following URL: http://www.w3.org/TR/xslt explains in details each of the XSLT elements and functions.
[13] The following URL: http://www.w3.org/TR/xsl/ explains in details the formatting objects procedures that can be applied to the content of XML result trees.
[14] Hypertext Markup Language specification (HTML) is the main presentation format of XML result trees. HTML is considered as the main markup language for publishing hypertext on the World Wide Web. Until HTML version 4.01, HTML was an application of SGML [7] [6] [5]. Since the introduction of XHTML recommendations, XHTML is an XML markup language application [15].
[15] Given that an HTML document can be modeled with a rooted tree graph and every HTML node has its own semantic presentation based on CSS, XML processors .Formatters. do not need to process XSL-FO files [29]. XSL-FO files are processed when the presentation format is not any of the World Wide Web presentation format specifications (e.g., pdf, txt, ps). At http://www.w3.org/TR/xsl/ you can find the set of XSL formatting objects that can be applied to the content of XML result trees.