Table of Contents
Abstract
The identification design space locates agents, identifies resources stored in agents. resource repositories, and indicates to the interaction design space the access mechanism of resources. In order to comply with interoperability, evolution, and decentralization design principles, World Wide Web technology designers created the Uniform Resource Identifier (URI) Internet standard [10]. A URI is used to locate, identify, and indicate the access method of resources stored in agents. repositories. As a result, URI is the main identification method of resources of World Wide Web technology.[3]
Figure 3.1 represents the design space tree of the identification design aspect. The Uniformity design aspect consists of the common interpretation of different types of resource identifiers among agents. The resource design aspect is the conceptual mapping to a resource or set of resources. The identifier design aspect is an object that can act as a reference to something that has an identity.[10]
To assure the same interpretation of a URI among agents, the uniformity design aspect must guarantee that there is a common syntax across different types of resource identifiers. The syntax of a URI basically specifies the name of resources, the access mechanism of resources, and the network location of agents.
The generic syntax of an URI is as follows: <scheme>://<scheme-specific-part>. The <scheme> component embodies the access method of resources (e.g., http, ftp, smpt). The <scheme-specific-part> component locates agents and identifies resources stored in agents. repositories.
URI can be classified as locator (Uniform Resource Locator) or name (Uniform Resource Name). A Uniform Resource Locator (URL) is a subset of URI components that identifies the access mechanism of resources, agent's network location, path of resources, and fragment identifiers. A URN does not identify the physical location of the resource because it is a subset of URI components designed to easily map namespaces into a URN-space.
The generic syntax of a URL is as follows: <scheme>://<authority><path>?<query>. The <scheme> component embodies the access method of resources. The authority component can be composed of the following: <user>:<password>@<host>:<port>. The user and password components are optional. The presence of the latter components depends on the scheme (e.g., The File Transfer Protocol scheme allows the inclusion of these two parameters). The host and port component indicate the network location of agents and the port number of the agent to connect to. The host component defines the Fully Qualified Domain Name (FQDN) of the agent, or the agent.s IP address (e.g., www.gwu.edu / 128.164.127.251:80). The path component indicates the location of the resource to be found in the agent.s virtual file system. The query component, also known as a fragment identifier, is used by agents to retrieve information on the identified resource.
In order to ensure consistent interpretation of URIs among agents, each of these components and parameters are joined by a set of reserved characters. The latter enable agents to parse and identify the parameters indicated by each component. For example, the following URL, http://www.caida.org/home/about/faq.xml#caida, indicates the access mechanism of the resource .HTTP., the network location of the server agent FQDN: .www.caida.org / 192.172.226.78:80., and the location of the resource located in the agent's virtual file system "/home/about/faq.xml#caida".
A URL can be absolute or relative. An absolute URL identifies explicitly the <scheme>, <authority>, <path>, and <query> URI components. In contrast, a relative URL indicates only the <path> and <query> URI components.
If an agent has parsed the absolute URL: http://www.caida.org/home/about/faq.xml#caida presented in the previous example; the user agent is then instructed to retrieve the following relative URL "faq.xml#purpose". It is not necessary to take a further step to link to the resource "faq.xml#purpose" with an absolute URL. This is because the location and access mechanism of the resource were identified by the previous absolute URL: "http://www.caida.org/home/about/faq.xml#caida". The relative URL "faq.xml#purpose" identifies two URI components <path> and <query>. In this case the path of the resource is /home/about/faq.xml and the query is #purpose.
Uniform Resource Names are intended to serve as persistent, location-independent, resource identifiers and are designed to easily map other namespaces into URN-space.
The generic syntax of a URN can be represented by: <URN> ::= "urn:" <NID> ":" <NSS>. A URN uses the string "urn:" to identify the scheme. NID specifies the Namespace Identification, and NSS specifies the Namespace-Specific String. For example, the following XML document instance maps each of its elements to the namespace called urn:com:library-oas-us:
<section xmlns='urn:com:library-oas-us'> <title>Landnet</title> <project> <author name="USAID" /> <book title="Lands of the American Continent" price="$35.95" /> </project> </section>
This is explicitly shown with the following XML document:
<{urn:com:library-oas-us}section>
<{urn:com:library-oas-us}title> Landnet </{urn:com:library-oas-us}title>
<{urn:com:library-oas-us}project>
<{urn:com:library-oas-us}author name="USAID" />
<{urn:com:library-oas-us}book title="Lands of the American Continent" price="$35.95" />
</{urn:com:library-oas-us}project>
</{urn:com:library-oas-us}section>
The use of Uniform Resource Names in XML documents allows communities to name their own elements in order to avoid name collisions. Therefore, communities can share XML document models easily because each XML element is identified by the name space chosen by the community.[11]
The World Wide Web technology is an application of the Internet network. This means that the World Wide Web technology uses the Domain Name System (DNS) standard protocol to search the IP address associated to the agent.s FQDN [13]. DNS is a client/server distributed database that is composed by domain name servers and resolvers. A resolver is used by agents to send a query to domain name servers, the IP address of the FQDN indicated by a URI. At this stage, the agent is able to establish a TCP or UDP connection in order to retrieve the resource identified by the URI.
A user in Figure 3.2 uses a user agent .Konqueror Web Browser. to submit the following URL: http://www.debian.org/. The user agent parsed the URL and determined that:
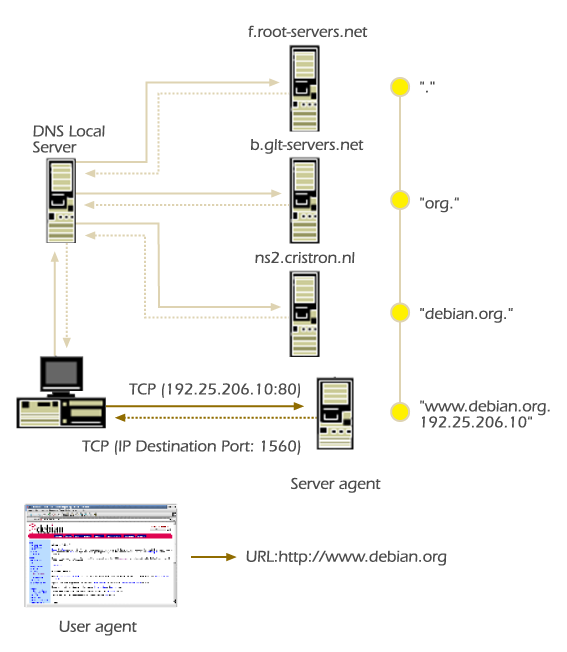
The scheme to access the resource is the HTTP protocol.
The FQDN of the server agent is the domain name "www.debian.org.".
The resource path is the root directory "/" of the virtual file system of the server agent.
In order for the user agent to be able to determine the IP address associated with the FQDN it uses the resolver's function gethostbyname(), then the resolver queries the domain name system. Once the resolver obtains the associated IP address for the FQDN "www.debian.org." the user agent is able to establish a HTTP TCP connection with the server agent and then retrieve the programmed default resource "index.en-us.html". Once the user agent has completely received the requested resource the user agent parses the resource and presents it in a readable format to the user, in this case the format is HTML.
The resource design aspect is the conceptual mapping to a resource or set of resources. A resource can be anything that has an identity; as a result a resource can be identified by a URI.
The relationship between World Wide Web resources can be modeled as a directed graph, whose nodes are a set of World Wide Web documents and whose edges are the links between resources [16]. The resource design aspect uses a URI to establish an explicit relationship between resources. The explicit relationship between resources is known as a link. A link has a starting resource point (starting resource) and an ending resource point (ending resource). Following a link for any purpose (e.g., average distance between World Wide Web documents) is called traversal. The way a pair of resources is traversed is known as an arc. The indegree of a resource x is the number of adjacent linked resources directed towards the resource x. The outdegree of a resource x is the number of adjacent linked resources directed outwards from the resource x.
An outbound arc is when a local starting resource links to a remote ending resource (e.g., a resource from a local HTML web page links to a remote resource). An inbound arc is when a remote starting resource links to a local ending resource. If the starting resource and the ending resource are not local then the arc is a third-party arc.
Usually, arcs are outbound. But when the starting resource point of a link is remote, which is the case of inbound and third-party arcs, there is no way of knowing where to find the remote starting resource point. In order to deal with this situation, let us introduce the concept of link databases also known as linkbases. A linkbase is an XML document that contains a collection of inbound and third-party links. When a linkbase is specified as the ending resource point of an outbound arc, agents will be able to load the linkbase XML document and extract inbound links or third-party links for later use. In this manner, it is possible to create inbound and third-party links between World Wide Web resources.
In the World Wide Web technology there is a set of specifications that define a set of constructs specifically designed to establish links between World Wide Web resources using URI. The main construct to establish a relationship between HTML documents is the element A[17]. On the other hand, the main specification for establishing links among XML resources is the XML Link.
The main link constructs for the HTML specifications are the elements A and BASE. The A element is used in the body section of an HTML document and can only be used to define outbound links, whose starting and ending resource points are specified by the content of the A markup and the value of its attribute "href" respectively. Given the way that the A element has been defined in the DTD of the HTML specifications, every link can only be outbound and it is not possible to define the way a pair of resources is traversed [18].
The function of the BASE element is to allow authors to specify in HTML documents the scheme access and authority components of the URI's website . In this manner all the links defined in an HTML document are specified by relative URLs. For example, the following HTML document is composed of one BASE element, and one A element:
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"> <html> <head> <title>The World Wide Web</title> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <base href="http://www.newdevices.com/"> </head> <body> <a href="sitemap/index.html"><p>Site map</p></a> </body> </html>
The BASE element indicates the scheme access and authority components of the URI's web site http://www.newdevices.com. The A element links the starting resource <p>Site map</p> to the ending resource sitemap/index.html, creating an outbound link.
Due to the fact that the XML specifications are the main specifications in the World Wide Web technology for representing and sharing information, the link specifications for the XML specifications has been designed to allow authors to:
Create inbound, outbound and third-party links.
Define traversal rules.
Define links with multiple ending resources.
Describe relationships between resources.
The main construct to establish relationships between XML resources is the XML Link (XLink) specifications [16]. XLink is an XML application that has its own namespace and a set of attributes that any XML element can use to establish links among XML resources. In order to implement XML document instances that include the use of XLinks, agents must be programmed to interpret XML document instances containing XLink elements and attributes.
In order to establish relationships between XML resources, the XLink specifications offer authors a total of 10 global attributes that are used in XML elements to define the following 4 essential parameters[19]:
Resource definition.
Resources involved.
Arc rules.
Description of resources.
The "resource definition" defines the resources to be linked. The parameter "resources involved" defines the resources linked by an XLink. The "arc rule" parameter defines the type of arc "inbound, outbound or third-party," as well as the event that activates the link traversal and the desire presentation of the ending resource[20]. The description of resources indicates the meaning of resources within the context of a link[21].
The XLink specifications allow authors to create two types of links: simple and extended. Simple links are used to define outbound links that are composed of a local starting resource and a single ending resource. The traversal direction is defined by the XLink "href" attribute. The properties of this type of link are the same as those found in the A link construct of the HTML specifications, with the exception that a simple XLink can be described and the A construct does not have link description capabilities. For example, the following XML document uses the XLink specifications to establish a simple XLink; where the starting resource is the content of the XML markup "colour" and the ending resource is the URL indicated by the value of the XLink attribute "href".
<?xml version="1.0"?> <wall xmlns:xlink="http://www.w3.org/1999/xlink">; <colour xlink:type="simple" xlink:href="http://www.123.com/colour.xml">Wall colours</colour> </wall>
On the other hand, extended XLinks allow authors to create inbound, outbound, or third-party links, define traversal rules, define links with multiple ending resources, and describe relationships between resources. The XML document outlined below is composed of two extended XLinks that establish the following relationship:
The content of the XML starting local resource "<colour XLink Attributes>Wall Colors</colour>" links to a remote ending resource XML document: "colour-list.xml", whose arc is an outbound arc that will be activated on request. Once the link has traversed the remote ending resource, the agent will replace the starting local resource.
The content of the XML starting local resource "<ext-colours Attributes> External colors </ext-colours>" links to a remote ending resource linkbase: "other-colours.xml", whose arc is an outbound arc that will be activated on load. Once the agent has traversed the link, the former will extract the inbound links located in the linkbase "other-colour.xml" for later use.
<?xml version="1.0"?> <wall xlink:type="extended" xmlns:xlink="http://www.w3.org/1999/xlink">; <!--First extended XLink. Local starting resource definition --> <colour xlink:type="resource" xlink:label="local" xlink:title="Wall Colors">Wall Colors</colour> <!--First extended XLink. Remote ending resource definition --> <list xlink:type="locator" xlink:href="colour-list.xml" xlink:label="remote" xlink:title="List of colours"/> <!--First extended XLink. Arc rule --> <go xlink:type="arc" xlink:from="local" xlink:to="remote" xlink:show="replace" xlink:actuate="onRequest" /> <!-- Second extended XLink. Local Starting resource definition --> <ext-colours xlink:type="resource" xlink:label="other-colours" xlink:title="External colours">External colours</ext-colours > <!-- Second extended XLink. Remote ending resource definition --> <other-colours xlink:type="locator" xlink:href="other-colours.xml" xlink:label="Colours-from-SW" xlink:title="Other Colours" /> <!-- Second extended XLink. Arc rule --> <go xlink:type="arc" xlink:from="other-colors" xlink:to="Colours-from-SW" xlink:arcrole="http://www.w3.org/1999/xlink/properties/linkbase" xlink:actuate="onLoad" /> </wall>
XLink constructs can use the XML Pointer (XPointer) specifications to retrieve information on the identified resource. The XPointer is a language that uses the fragment identifier component of a URI used to locate and identify XML element resources that are part of the retrieved XML document.
For example, the following URI http://caida.org/home/about/faq.xml#xpointer(id(faq1")) has the following fragment identifier "xpointer(id(faq1)", which is an XPointer expression. When this XPointer expression is parsed by the agent, the agent will be able to locate the XML element with an ID attribute equal to "faq1"[22].
The XPointer specification is an extension of the XML path (Xpath) specifications. XPath is a declarative language for addressing the XML elements that compose an XML document; in addition XPath is a pattern-matching language that shares a common data model with XSLT and XQuery specifications[23].
A resource can be viewed as an object that has an identity, and is therefore identifiable. A URI is the main method of identifying resources World Wide Web technology resources. For this reason, communities must assign a URI to each resource in order for the resource to be identifiable and accessible[24].
[16] World Wide Web graph models are used to define algorithms (e.g., search engine algorithms). In actuality there are different World Wide Web graph models. Some of them focus on the graph structure at the level of World Wide Web documents (e.g., the copy model) [13], other models include the hierarchical relationship among different levels of resources like host domain names, web sites, and World Wide Web documents (e.g., Hostgraph model) [14].
[17] In the HTML specifications there are several HTML elements that are used to create links between resources (e.g., IMG element, SCRIPT element). In this section we will only view the elements A and BASE.[15]
[18] In the HTML specifications some elements are used to establish inbound links (e.g., IMG element), which embeds an image in an HTML document.
[19] The global attributes are type, href, role, arcrole, title, show, actuate, label, from, and to.[16]
[20] The XLink actuate attribute defines the event that activates the link between two resources whose possible values are onload, onrequest, other, and none. The XLink show attribute defines the presentation of the ending resource whose possible values are new, replace, embed, other, and none.
[21] The XLink attributes role, arcrole, and title are used to describe the meaning of resources.
[22] The XPointer specifications have been split into four specifications: XPointer framework, XPointer xmlns() scheme, XPointer element() scheme, and Xpointer() scheme. The XPointer xmlns() scheme is intended to be used with the XPointer Framework to allow correct interpretation of namespace prefixes in pointers. The XPointer element() scheme is intended to be used with the XPointer Framework to allow basic addressing of XML elements. The XPointer xpointer() scheme is intended to be used with the XPointer Framework to provide a high level of functionality for addressing portions of XML documents. It is based on XML Path specifications (XPath), and adds the ability to address strings, points, and ranges in accordance with definitions provided in DOM 2 specifications. [17][18][19][20]
[23] The following URL http://www.w3.org/TR/xpath#data-model links to the XPath data model, which is the reference for the data models used by the XSLT and XQuery specifications.
[24] The only identification mechanism that has been mentioned in this chapter is the Domain Name System (DNS). However, it is important to mention that there are many identification mechanisms implicitly involved during the identification of a resource by a URI (e.g., MAC address addressing scheme, IP addressing scheme, DNS, AS addressing scheme).